
Lo TAL (tractament automatic del lengatge) e las tecnologias de la lenga en occitan an conegut d'avançadas màgers aquestas darrièras annadas. La fuèlha de rota pel desvolopament del numeric occitan, en 2014, aviá fixat d'objectius que la màger part son estats completats. L'occitan a uèi un bon nombre d'otisses de tractament automatic del lengatge, mas de trabalh demòra encara a far.
Vos prepausam aquí un estat dels luòcs, otís per otís e ressorsa per ressorsa, de çò qu'existís per l'occitan, de çò que demòra a bastir e de las ressorsas qu'existisson per çò far.
Avèm ensajat d'èstre exaustius, mas se avètz coneissença d'una informacion que nos a escapat, esitatz pas a nos contactar mercés al boton en bas de pagina.

Lo traductor automatic occitan qu'a servit de basa a la màger part dels autres es lo traductor liure Apertium. Es a partir d'aquel que foguèron bastit Revirada del Congrès (en partenariat amb Elhuyar), lo de Softcatalà, lo de la Generalitat de Catalunya e lo d'Opentrad.

La sola sintèsi vocala occitana qu'existís a l'ora d'ara es Votz, la sintèsi vocala per l'occitan gascon e l'occitan lengadocian del Congrès, desvolopada en partenariat amb Elhuyar. Foguèt realizada dins l'encastre del projècte europèu Linguatec. Lo projècte Linguatec AI, obèrt dempuèi 2024, a per objectiu de la melhorar e d'i integrar l'occitan aranés mercés a un trabalh del Congrès, d'Elhuyar, de Col·lectivaT e de SoGeL.

Un primièr motor de reconeissença vocala (occitan gascon e occitan lengadocian) es estat desvolopat pel Congrès e Elhuyar dins l'encastre del projècte ReVoc, mas l'otís a pas per ara d'interfàcia utilizator. Lo projècte Linguatec AI a per tòca de ne crear una e d'ajustar l'occitan aranés a las varietats presas en carga.

Existisson mantun corrector ortografic per l'occitan : lo Dicodòc del Congrès (fait en partenariat amb Elhuyar), lo creat mercés a Dicollecte e l'Aranese spell checker son los mai conegut, mas n'existisson d'autres. La màger part foncionan per LibreOffice, Firefox, Chrome e Mozilla Thunderbird.
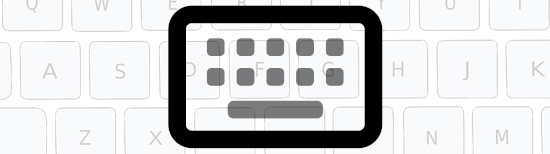
Los clavièrs predictius en occitan existisson sonque per Android (aquò perque lo còdi font per far de clavièrs iPhone es pas public, al contre del d'Android). Existís pas, pel moment, que lo clavièr Swiftkey e lo GBoard de Google qu'intègran l'occitan, mas prenon pas en compte la varietat e prepausan mai que mai de mots lengadocian.
CLLE a realizat de modèles d'entraïnament per dos otisses de reconeissença de l'escritura (OCR) : Jochre e Tesseract. Quentin Pagès prepausa tanben de modèles per Tesseract, PaddleOCR e EasyOCR.

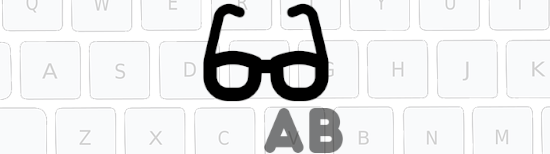
Nombroses otisses permeton de detectar la lenga d'un tèxte escriut, e la màger part prenon en compte l'occitan. Per çò qu'es de la reconeissença orala, existís almens un otís que sap reconéisser l'occitan. E per diferenciar las varietats de l'occitan, i a sonque un programa en desvolopament.

CLLE a realizat un tokenizaire qu'a integrat dins son analisator sintaxic Talismane. Existís tanben lo tokenizaire octokenize e Lo Congrès es a bastir lo sieu, que serà accessible mercés a una API.